
Distributed Systems - Single leader Replication
Single Leader Replication : Part 1

Below content is my notes from this wonderful book - Designing data intensive applications by Martin Kleppmann.
Introduction
You must be using databases in your system but have you ever wondered what will happen if your database server goes down? Your customers might not be happy as your system won’t be able to persist the necessary information anywhere. So, replication is a solution to avoid this situation. In this article, I will mainly talk about the single leader replication.
Leader vs follower
Assume you were writing and reading from just one database server but as it is a single point of failure so, you decided to setup another node which follows the leader which means it stays in sync with your primary server. Leader is sometimes called as primary or master and follower is called as slave, secondary or read replica.
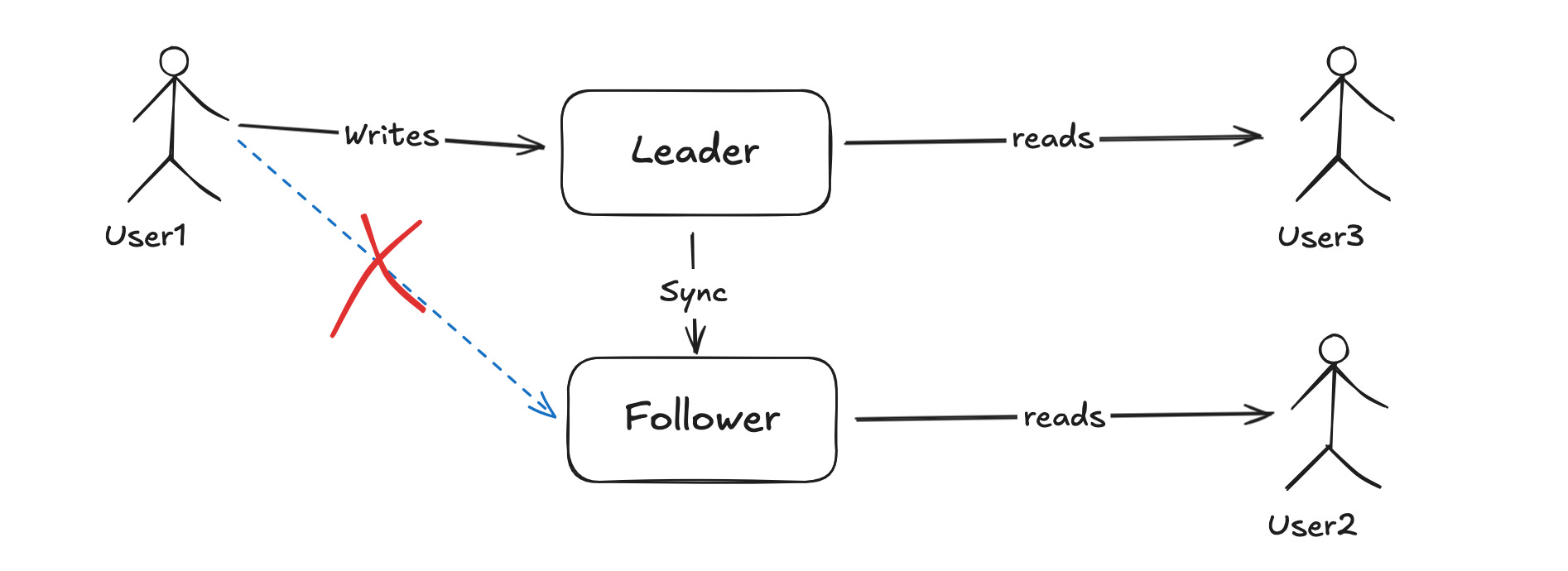
In single leader replication, all writes happens on leader and reads are uniformly discributed across leader and its replicas. This solves the problem of availability but what about consistency between leader and the follower? We will talk about it later or in upcoming posts. For now, I can tell that in existing database solutions out there, follower is generally in sync with the leader with a max delay of few milli seconds to 1 s but I am not denying the fact that it can go in minutes and hours during network issues or heavy load on leader.
Synchronous vs Async Replication
As the name suggests - In Sync replication a write on leader node is considered as completed when it writes to all its replicas. In Async, leader doesn’t give a shit if the write to replica is completed or not.
Sync is good in the sense that all replicas will be consistent with leader. But it add a bottleneck and system might crash if one of the replicas shut down. As leader won’t be able to write on the faulty replica it won’t write in its own disk and prevent any future writes.
Async is good for availability but replicas might not be consistent and might stay far behind the leader. So, when a user make a read request to a replica, he might get a stale response. We will see some solutions for this replication lag and stale reads later.
MySQL and Postgres sql uses async replication by default.
Handling follower failure
What will happen if a follower node goes down? Follower nodes maintain the logs in their disk, so when it comes up it uses the logs to activate itself i.e. build required indexes in memory and then request the leader to send the data changes after the last transaction which happended before it crashed.
Handling leader failure
This is tough because when a leader fails, we need ways to detect that leader has failed. There is no foolproof way but if leader doesn’t respond for some x seconds then it can be considered crashed. Once it is detected, followers need to decide who can become a new leader. The best choice is the one having the latest updates. Third thing is to reconfigure the system to make write calls to the new leader.
But what if new leader comes up all of a sudden? This is called a split brain situation when two nodes call themselves as leaders. There are some ways to solve this but shutting down the old leader if it comes back again. But this is a scary situation and if not handled properly, it can cause problem for the application.
Also, in case of async replication, follower might not be up to date with the leader then what?
We will talk about them later as soon as I learn about the solutions myself. :p
What is actually sent to followers while replication?
Statement based replication - Just send INSERT, UPDATE, DELETE statements to the follower and it can execute it like the leader. But the main problem with this is that any calls to non-deterministic function like NOW() will break the consistency between leader and the follower. Volt db uses it but by enforcing its transactions as deterministic.
WAL shipping - WAL means Write ahead log which is a special log maintained by the databases in the disk while writing. It is an append only sequence of bytes containing all writes to the db. Leader sends WAL to its followers for replication. Postgres and Oracle uses this for replication. Problem is WAL describes data at very low level which makes it tightly coupled to the storage engine. It is problematic in cases when db wants to update its storage format as a form of some improvement and this will led to downtime.
Logical/Row based log replication - An alternative way is to use row based replication which allows the replication log to be decoupled from storage engine internals. Here only the changes which are made in specifc rows are sent to the replicas along with the operation like INSERT, DELETE.
Replication lag problems
Reading your own writes - For ex, you’ve made some updates in your social network profile and you read it from the replica, you might see that changes are not reflected. So, what you can do it to read your profile from master node and others profile via replicas to avoid such scenarios. Facebook does that. Other techniques can be used to decide when to read from the leader based on the requirements.
Monotonic reads - A user can see updated data when read from an up to date replica but when it reads from another replica, it can see older data which is like traveling back in time. Monotonic reads is a guarantee that this situation doesn’t happen. One way is to make sure client make calls to the same replica instead of multiple replicas. You need to route the request to right replica based on user id.
Consistent prefix reads - This is a problem particularly in sharded databases. Lets say there is a whats group of three people. Two of them are chatting and third one is observing. User 1 asked a question to user 2 and lets say leader of partition 1 writes the question. User 2 responded with answer which is stored in leader of partition 2. Now, to the observer it might happen that answer reaches before the question as both are written to different partitions. Solution is to write casual related writes can be written in same partition. For ex. chat database can be partitioned on group id.
Solutions to replication lag
We have discussed some solutions at application level like reads can go to leader for sometime and after a certain time reads can go to replicas as well. But implementing at application or client level is complex and it is easy to get wrong.
I don’t think there is a single solution to this - We can either live with eventual consistency where replicas will eventually sync with the leader or we can write some application code to make sure the reader reads from the correct place.
This is it for today! I will see you in another blog where I will talk about multi leader replication!