
LLM Fundamentals Every Software Engineer Should Know – Part 1
In this article, we will talk about two main fundamental topics in LLMs - Tokenization and Embeddings.


1. Introduction
Large Language Models (LLMs) are powerful, but they are not mysterious black boxes. At their core, they are built through a well-defined pipeline: the transformation of raw text into tokens, embedding those tokens into vectors, and then processing them via deep neural architectures. In this first part, we will dive deep into tokenization and embeddings — two foundational steps that convert human text into a form that LLMs can process. Understanding these is critical: mistakes or inefficiencies here propagate through the entire model, affecting cost, performance, and generalization.
2. Tokenization
Tokenization is the process by which raw text is broken into discrete units (“tokens”) that the model can handle. Without it, the model cannot map text to numbers, handle rare or unseen words properly, or work efficiently on long sequences.
2.1. Why it matters?
Here are the key functions of tokenization in LLMs:
Compact Vocabulary: Keeps the number of tokens manageable.
Flexibility: Handles unseen or rare words via subword decomposition.
Efficiency: Shorter sequences mean less computation per forward pass.
Cost: If you have used any LLM models then you know that cost is directly associated with number of input and output tokens.
Consistency: Defines uniform units for next-token prediction.
2.2 Tokenization Strategies
Let’s take an example sentence: “Unbelievable performance is coming.”
Here are different tokenization approaches:
2.2.1. Character-level
Tokens → [”U”, “n”, “b”, “e”, “l”, “i”, “e”, “v”, “a”, “b”, “l”, “e”, “ “, “p”, …]Pros: Can represent any string, even misspellings or novel symbols.
Cons: Very long sequences; each character carries almost no semantic weight.
2.2.2. Word-level
Tokens → [”Unbelievable”, “performance”, “is”, “coming”, “.”]Pros: Intuitive, simple.
Cons: Rare or new words (e.g., “unbelieveably”) may not be in vocabulary; vocabulary size blows up.
2.2.3. Subword-level
Tokens → [”Un”, “#believ”, “#able”, “performance”, “is”, “coming”, “.”]Pros: Balances vocabulary and generalization. Even if the entire word isn’t known, subword units likely are.
Two algorithms you should definitely explore are WordPiece and BytePair(used by GPT-2,3,4 and llama models) Tokenization.
Each subword token is then looked up in the tokenizer’s pre-trained vocabulary. If found, it’s replaced by its unique integer ID.

This vector is then passed to embedding layer of LLM to process further.
3. Embedding Vectors
Once we have tokens, the next step is to convert them into a numerical form the model can reason over: embeddings.
3.1. What Are Embeddings?
An embedding is a dense vector representation of a token in a high-dimensional space. Instead of treating tokens as discrete IDs, embeddings let the model capture nuanced relationships — semantic, syntactic, contextual — in continuous space.
Intuition via Analogy
Imagine a 3-dimensional “taste space”:
Dimension 1 (x-axis): Sweetness
Dimension 2 (y-axis): Saltiness
Dimension 3 (z-axis): Sourness
In this space(Object → Vector Representation → Interpretation)-
“Candy” → [89.4, 2.3, 4.5] → might have high sweetness, low saltiness, low sourness.
“Butter Chicken” → [1.1, 67.43, 3.2] → might have low sweetness, moderate to high saltiness, low sourness.
“Lemonade” → [6.3, 3.4, 98.76] → might have moderate sweetness, low saltiness, high sourness.
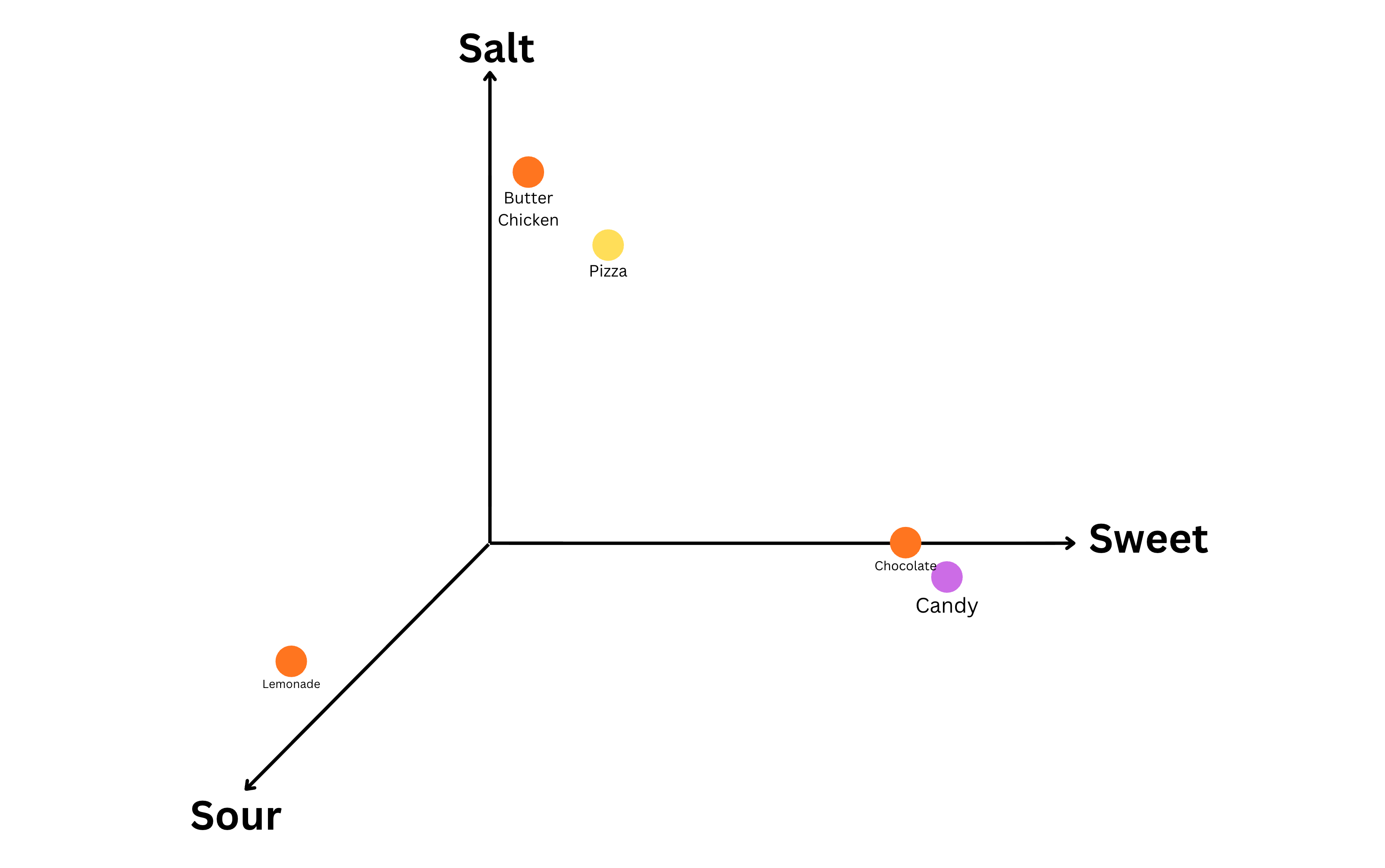
By placing food items in this 3D space, one easily reasons about similarity (candy vs chocolate vs lemonade) and trade-offs. Similarly, LLM embeddings place tokens in a high-dimensional latent space where proximity encodes meaning or usage.
3.2. Why it matters?
Semantic similarity: Synonyms or related words cluster (e.g., “run”, “jog”).
Syntactic roles: Words that behave similarly in grammar may lie near each other.
Contextual patterns: Because embeddings are updated via backpropagation through the transformer, they gradually encode common usage contexts.
Let vocabulary size = V, embedding dimension = d. The embedding matrix E is of shape V × d, where each row E[i] represents the vector for token i. During training, E is learned so that tokens used in similar contexts lie close together in this d-dimensional space.
In large LLMs, d can be very large (e.g., 768, 1024, or more). In some models, embeddings even reach dimensions like 12,288 latent features. These high-dimensional embeddings can compactly represent richly nuanced relationships among tokens.
4. Conclusion
Understanding tokenization and embeddings is not just an academic exercise — it’s the foundation upon which every Large Language Model operates. Tokenization defines how text becomes processable units, and embeddings define how those units acquire meaning in high-dimensional mathematical space. For software engineers, especially those building AI-driven systems, these components directly influence cost, latency, accuracy, and robustness. They dictate how models generalize across languages, handle typos, compress information, and learn semantic structure. Whether you’re designing an RAG pipeline, optimizing inference, or fine-tuning a model, your ability to reason about tokens and embeddings will shape the performance envelope of the entire system.
In coming parts, we will go deeper into transformer architecture, attention mechanism, and training mechanisms etc. connecting how these embeddings propagate through layers of attention to produce meaningful outputs.
5. References
An in-depth article on Tokenization - https://notes.suhaib.in/docs/tech/llms/how-tokenization-really-works-in-llms/
Hugging face articles on tokenization strategies - https://huggingface.co/learn/llm-course/en/chapter6/1
Embeddings explained - https://www.howdoai.org/en/transformer/embeddings-explained
Excellent analysis! I wonder if subword tokenization ever causes semantic issues? Such a smart explanation.