

Introduction
In this article, we will learn about a potential system design solution for an anonymous image sharing app which was asked in Google system design round. We will learn about requirements, capacity estimates, APIs, entities, block diagram and deep dives for this problem.
Requirements
Functional requirements
Upload a picture anonymously and get a url back.
Users should be able to see the image when they search for the respective url.
[Stretch] User can vote for bad images via a thumbs up/down button.
Non functional requirements
Available (service should be up always)
Availability > Consistency while uploading and opening it in few sec.
Security - Malicious/Bad image should be flagged.
Latency < 1 seconds.
Durable - Images should not be lost. Deletion should be based on the company requirement or usage of that image.
Capacity estimates
10M active users per month
90% only read and 10% upload.
Storage(assuming 2MB avg. size of image) -
Image - 1M images per month * 2 * 10^6 bytes = 2 * 10 ^ 12 = 2 TB per month = 2TB * 10 years * 12 months = 240TB for 10 years.
Image metadata - 1M images per month * 1Kb per image = 10^9 = 1GB per month = 120 GB for 10 years.
Read >>>>>> writes
Reads = 9M reads per month = 9M / 30 = 300K per day -> 300K read / 100K = ~3 reads per sec.
Writes
Metadata writes - 1M writes per month = 1M / 30 = 34K per day -> 34K / 100K = 0.34 writes per sec.
Vote write - Lets assume 20% of people vote for an image. 9M * 20% writes per month = 1.8M(or ~2M) writes per month. 0.68 writes per second.
Entities & APIs
Core entities
Image
Image Metadata
Url
APIs
We can get started with below APIs, but our API req and res structure might change based on the discussions during the interview.
POST /image -> 200, image_url
body = { imagemetadata…, image }GET /image?imageId= -> html<image_url>, 200, 4XX errors for invalid images or 5XX for server side errors.
POST /image/vote?imageId= -> 200
body = { isBad: Yes | No }
Getting started with simple design
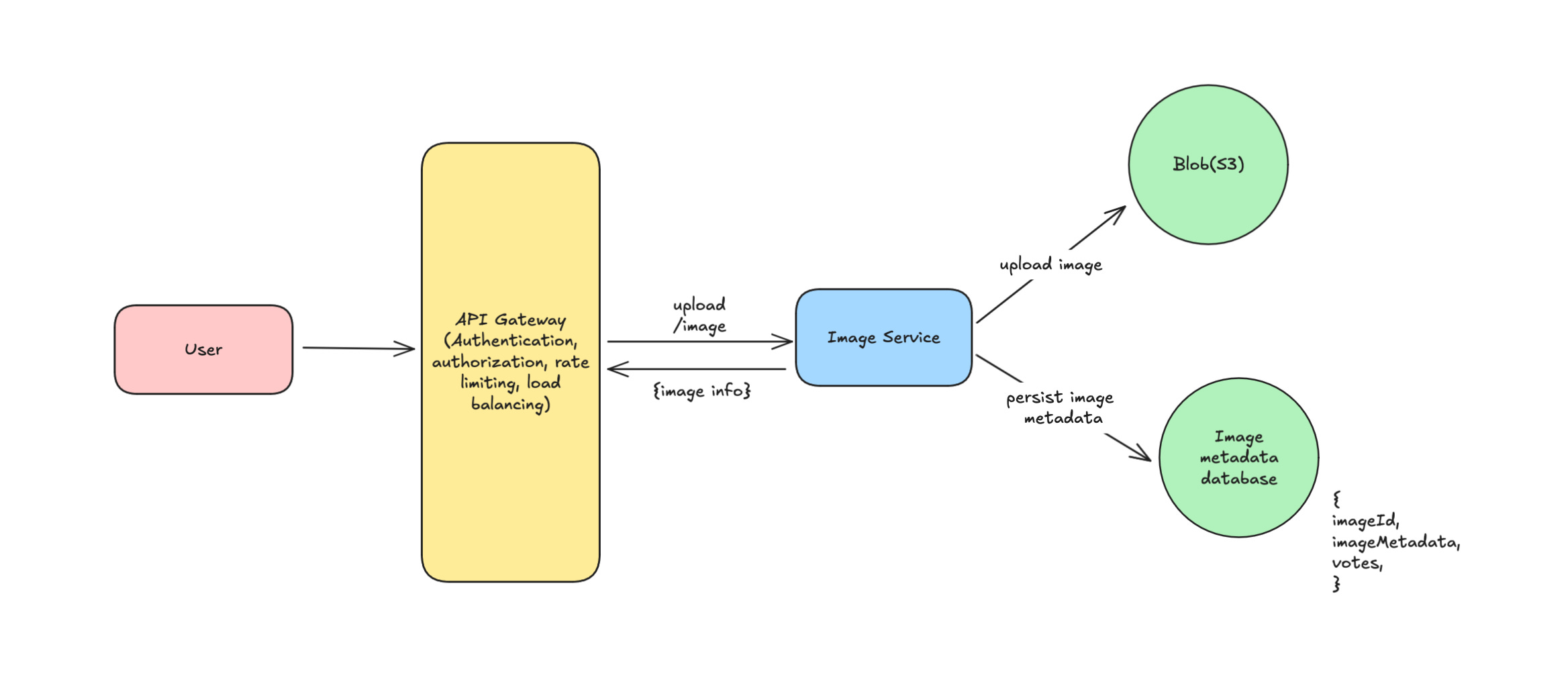
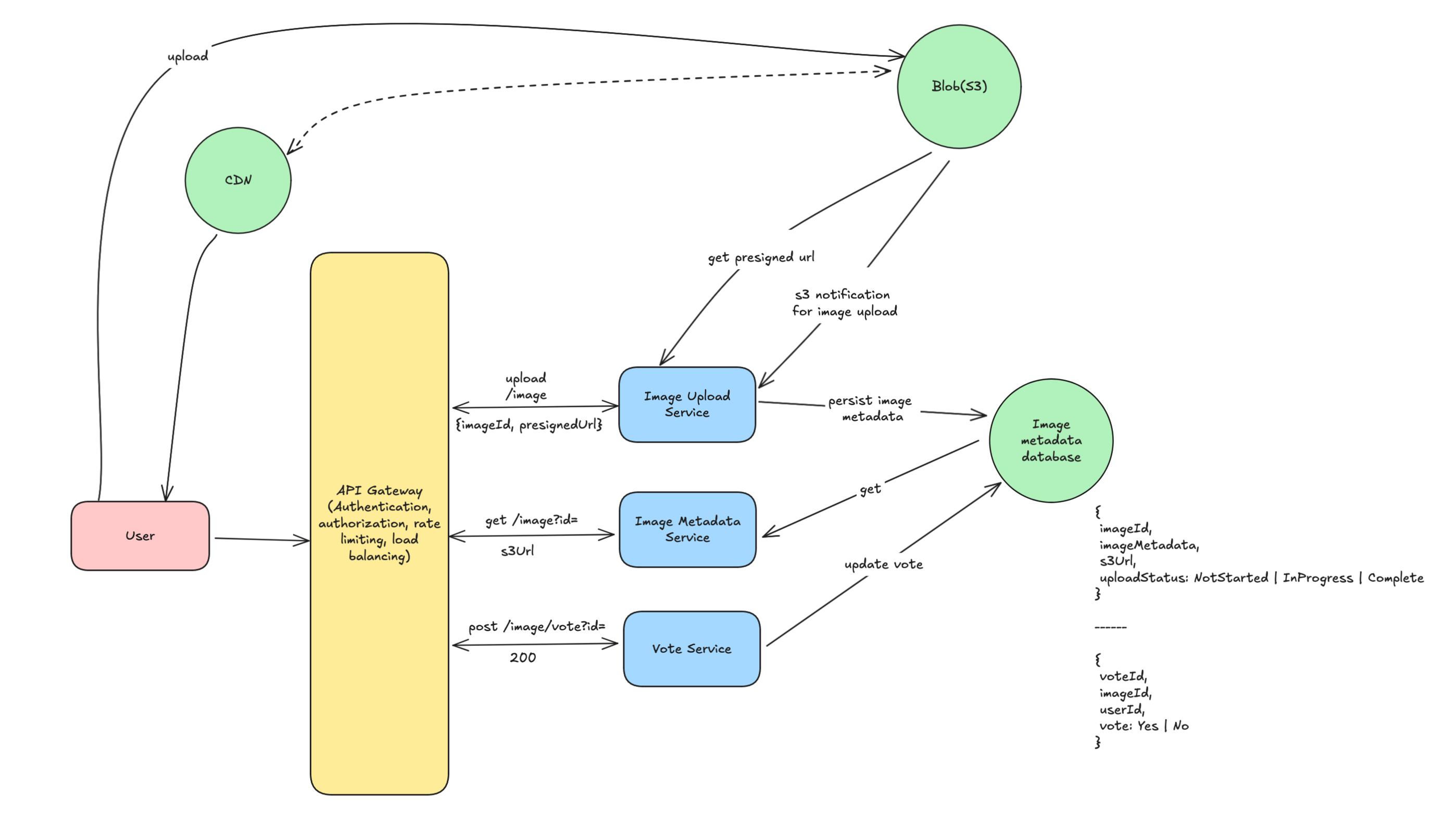
In above image, I have added an API gateway in front to abstract multiple things for the application like authentication, authorization, rate limiting etc. Image service is our main service which will host all the APIs and images will be stored in a blob storage like S3 and image metadata in a database. We can use any database based on capacity estimations so, I am going with postgres.
Users can get the image url from imageId by calling this https://imageservice/v0/image?id=1qt2hd34df3f32dw.
Metadata Database Record
{
imageId,
imageMetadata,
s3Url,
votes
} Deep Dives
What if image is uploaded to S3 but service failed to update metadata in db?
State management is tough and need solutions like two phase commit which have their own complexity and challenges. There is way to avoid that route- We can use something called pre-signed urls which will be provided to us by the s3 and the pre-signed urls are valid only for few hours/days based on our requirement. We can first create a record in our metadata db. If it succeeds, we will fetch the presigned url and pass it along with image id to the user and he will upload the image directly to S3. Image service will get S3 notification when image is uploaded and image service will update the s3Url and upload status in the db.
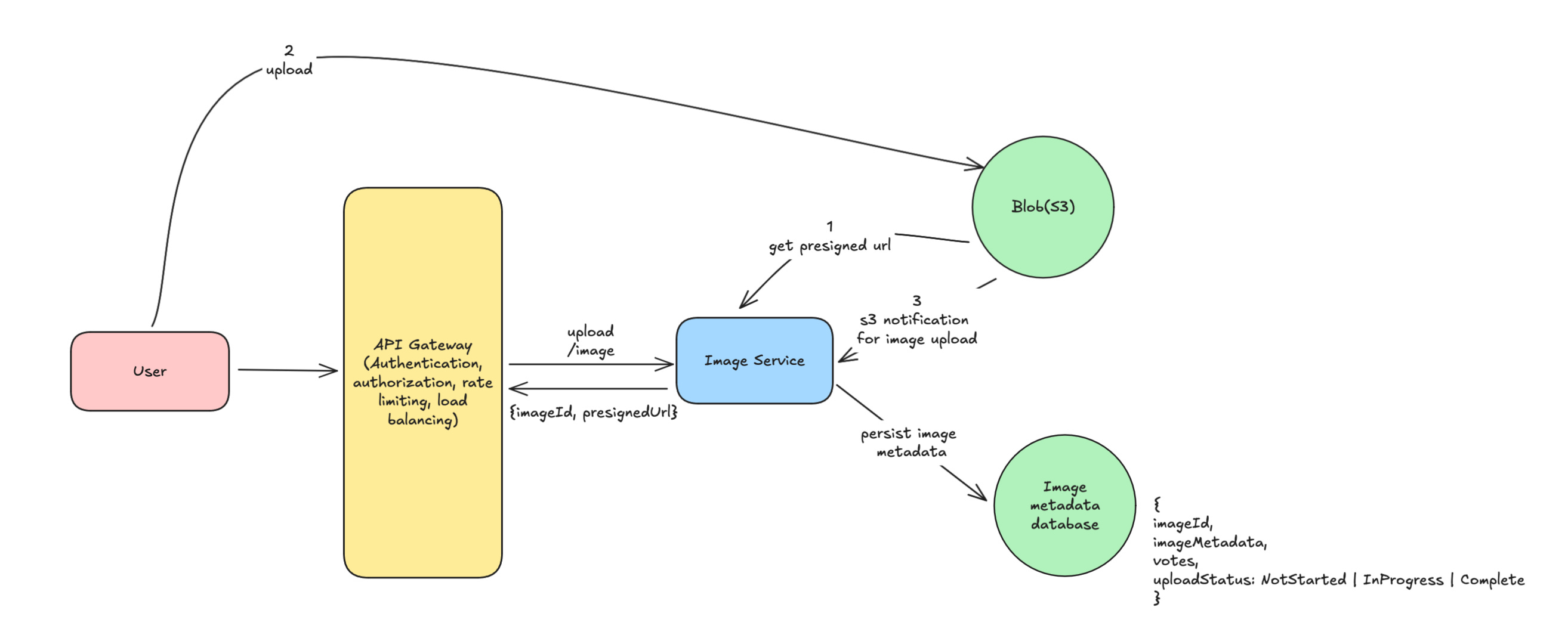
Metadata Database Record
{
imageId,
imageMetadata,
s3Url,
votes,
uploadStatus: NotStarted | InProgress | Complete
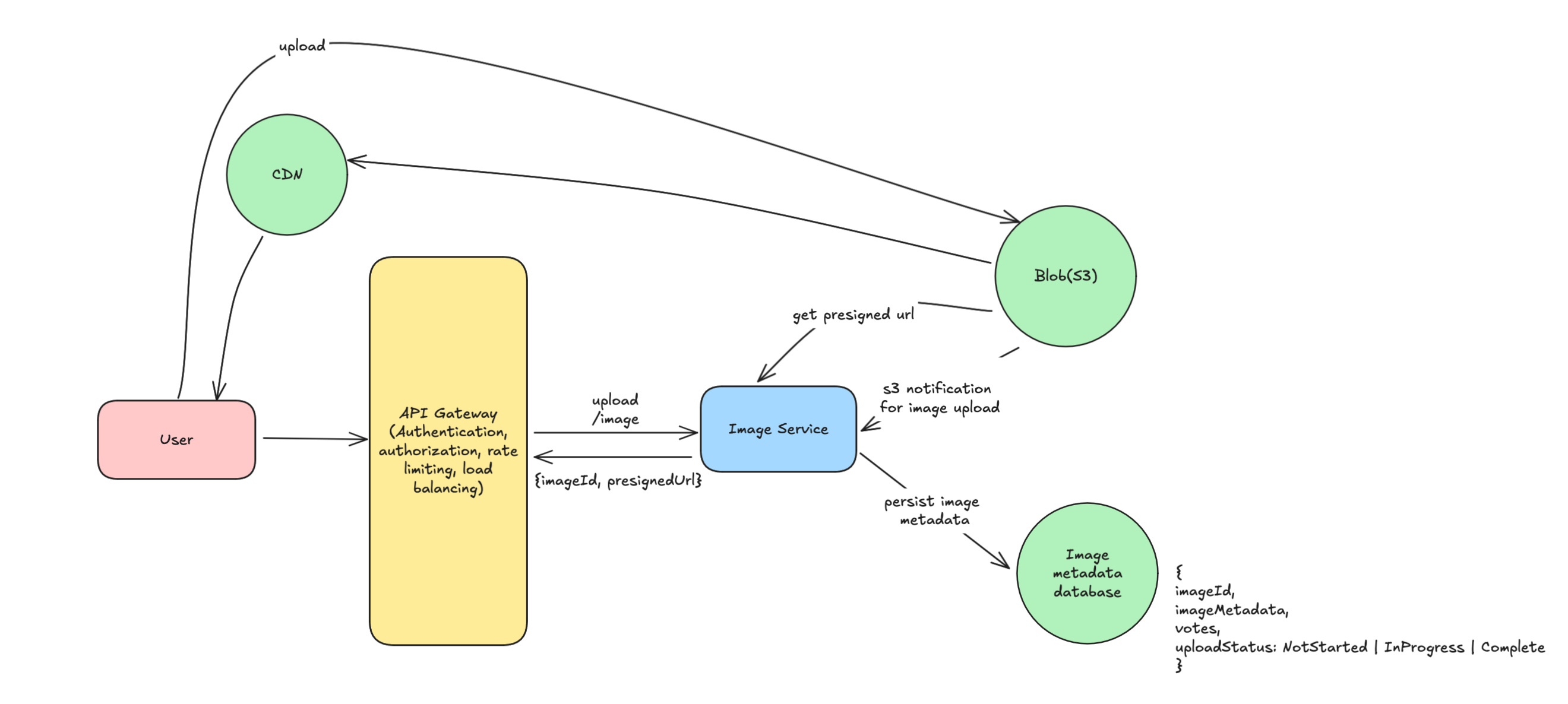
} How can we speed up image downloading for users?
We can use CDNs which is costly but if company is rich then who can stop them. Downloading will be fast as users can download the image from their local network via CDN.
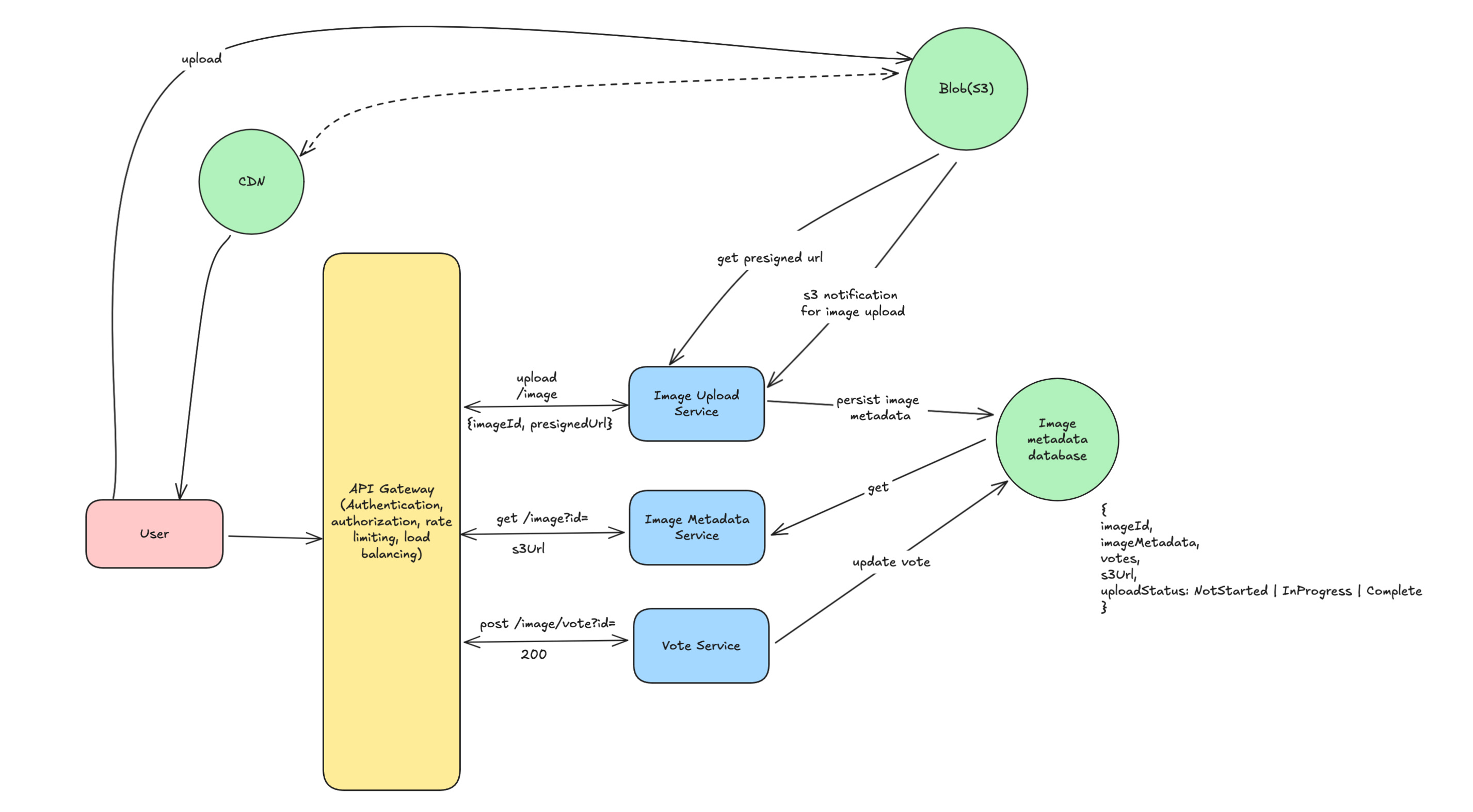
How to scale this solution?
Image service can be horizontally scaled as it doesn’t maintain any state. S3 is infinitely scalable solution provided by Amazon. Postgres db can be configured with master slave architecture so read replicas can handle increase read throughput.
But there is huge gap in read write ratio which 9:1. So, it is ideal to scale them separately and also it will help in reducing blast radius. Also, voting can be scaled separately.
What if someone keep voting again and again?
At client level we can stop this behavior to some extent by using cookies and avoid calling the voting api again. But user can invoke the api from incognito browser mode and update again. So, what can we do?
We can propose a solution where we can keep a separate table for votes given by a logged in user. We can quickly check if a user has already voted. Non-logged in user won’t be able to vote. See below table schema-
{
voteId,
imageId,
userId,
vote: Yes | No
}
Other optimizations
We can introduce a metadata cache for faster metadata reading.
We can talk about
Security -
User Identity Safety - keep user id info in the JWT Tokens.
DoS Attack - Rate limiting.
Hakcing vulnerabilities - Don’t keep un-necessary ports open for inbound traffic on databases.
Observability i.e. monitoring via dashboards and real time alerts on CPU, disk, heap after gc use and other business metrics.
Conclusion
This problem was not a tough one but it might be difficult to convince the interviewers in certain scenarios. So, please be well prepared. Also, an interviewer can ask more questions if there is more time during the interview. For ex. Interviewer extended this problem further for me by asking me to show the top k images of the day. So, be mentally perpared for the extended problems as well.
If you think any of the solution/optimization provided above are incorrect or doesn’t make sense, please feel free to comment.
Nice and informative post 🙌🏼
Great article, I enjoyed working through the follow up questions as I read!