
Distributed Systems - Multi-leader and leaderless Replication
Multi leader and leaderless replication : Part 2

Below content is my notes from this wonderful book - Designing data intensive applications by Martin Kleppmann!
Introduction
In previous article we have seen how single leader replication works. To summarize, In single leader replication, there is one node which is called leader and only it can accept writes whereas there are many other nodes which are called followers/replicas of leader node and reads can happen from any of them or from the leader as well. In this article, we will see what happen if there are multiple leaders who can accept writes or there is no leader at all?
Multi-Leader Replication
As the name suggests that there can multiple nodes which can accept writes. You can imagine when there are multiple leader nodes, how complex would it be manage conflicts and to maintain consistency. Generally due to its complexity it is generally not used and preferred to not use this style of replication. But there are certain use cases-
Multi data center operation - Lets think of facebook where people from anywhere in the world are posting and seeing content of the whole world. Single leader might work in a specific location but as the whole world needs to be connected we need multiple leaders and maybe one leader in every datacenter like us-east-1, eu-west-1, eu-south-2 etc. Benefits include - 1). If a nearest to a user datacenter is down, user can still access the data from another datacenter. 2). High speed as user can interact with the local datacenter which is async sending updates to other leaders in other datacenters.
Client with offline operation - Think of a calendar app which has local DBs in computer, mobile and other devices. When the devices are online they can sync to get on the same page.
Collaborative editing - Google docs is one such example where many people are writing at once on their local devices but eventually it is getting synced on every device.
Handling write conflicts
As there are many leaders, multiple users can update the date in different leaders and writes will be successful if we use async replication but there can be conflicts which will be detected later.
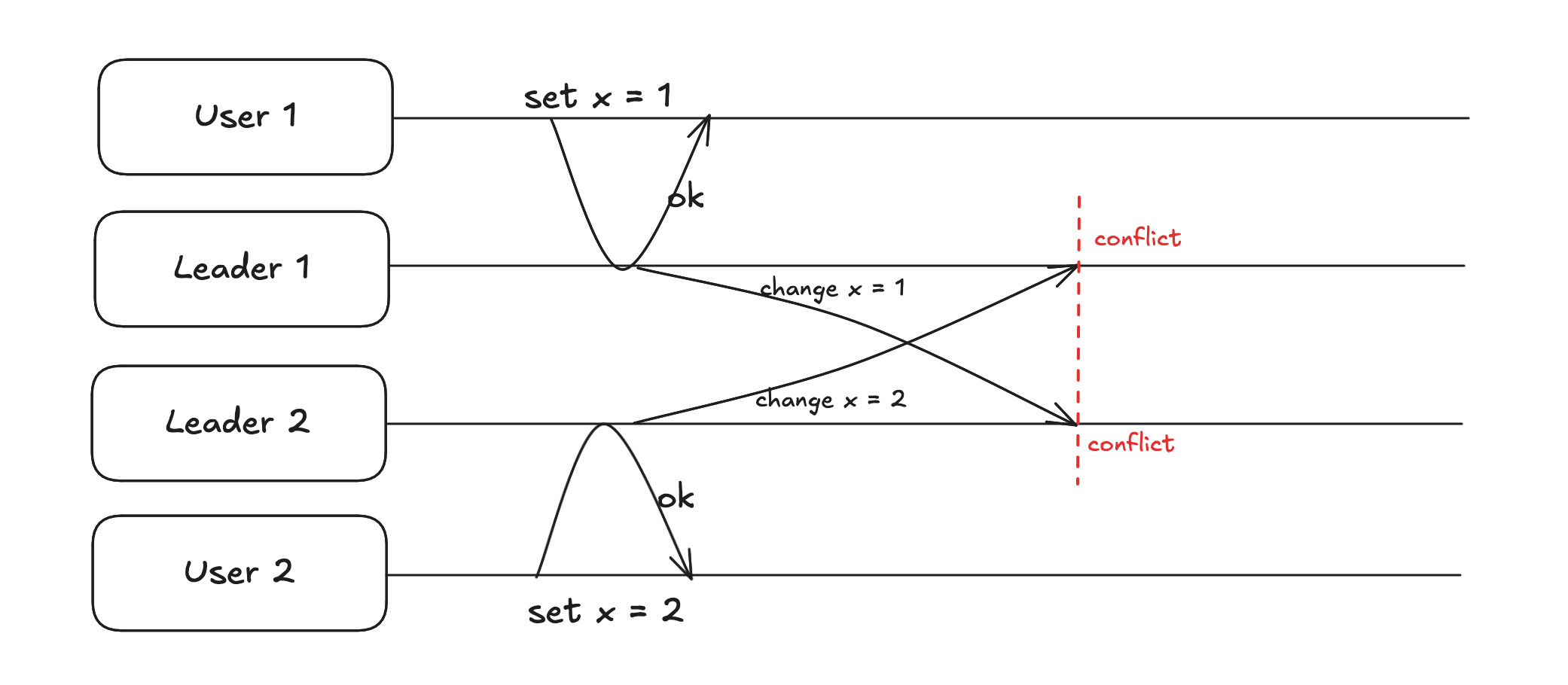
Sync replication can be used but it is pointless as it removes the added benefit of multi leaders.
Conflict avoidance - Best strategy if we can avoid the conflict by making sure that writes to the same key always go to the same leader. This is good but it might not work always. Think of a situation where user from India moves to Seattle and there he access facebook, it doesn’t make sense to send his writes to a datacenter in India as he will have to face high latency.
Converging towards a consistent state - If there are conflicts, database should decide a final value for that key when all changes have been replicated. One way is to use LWW(last write wins) where timestamps could be used but this can cause data loss due to clock skew problem. Another approach is to give every replica a unique id and value update from the highest replica id is accepted as final. Some database provides custom conflict resolution logic on read and writes. Conflict free replicate data types (CRDTs) can be used for conflict resolution. Riak db provides multiple CRDTs.
Multi-leader replication topologies
Most common is all to all but some databases support restricted topologies like MySQL by default uses cricular topology. Another popular one is star topology.
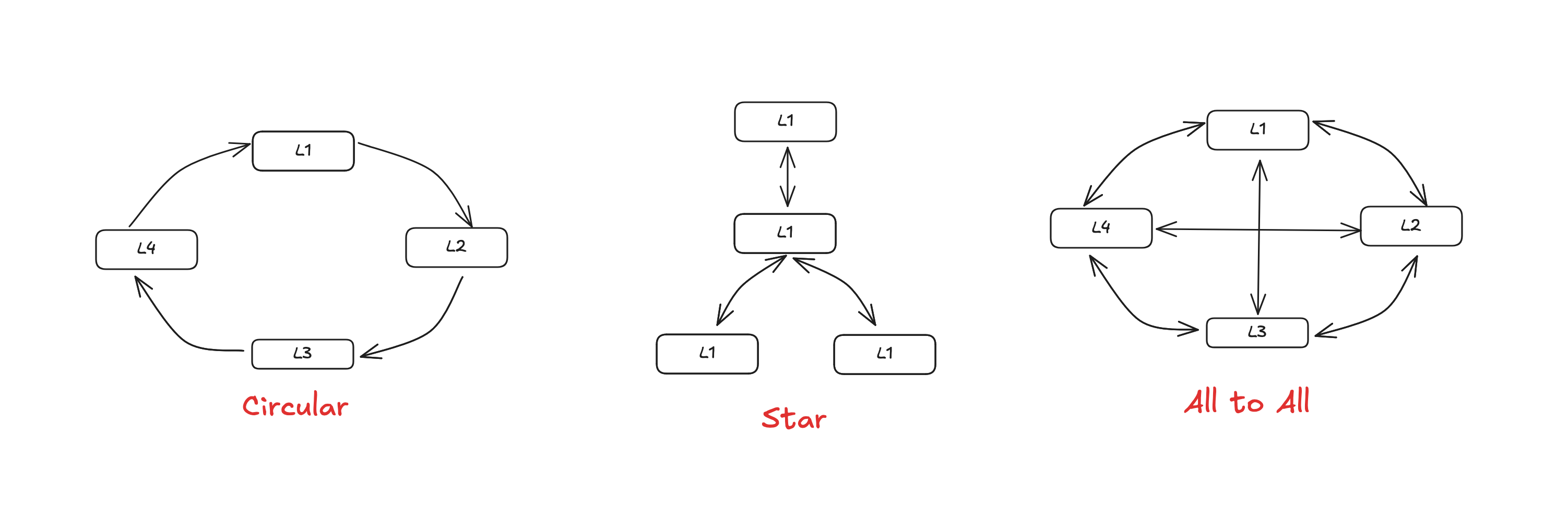
Problem with star to star or circluar topologies is the issues due to network interruptions as there is a single point of failure. There are some solutions around it but in general it involves manual effort. Fault tolerance of all to all is much better but there are some issues with it as well as writes might come in any random order to the nodes. For ex. an update op might come before insert op. Version vectors can be used to fix this but in general conflict resolution are poorly implemented in multi leader replication systems so, it is recommended to test thoroughly all edge cases before using these.
Leaderless replication
If you haven’t read the Dynamo paper then this section will be a little bit difficult to digest. In leaderless replication, client(or coordinator node) usually sends a read/write request to multiple replica nodes.
Writing to a database when node is down
Lets say you are writing to multiple nodes but one of the node is down and write was not successful there. But while reading that node will return the old value and other nodes will return the new value. So, how will the client decide which one to use? Generally version numbers are used to decide the latest value. So, if a replica is sending a response with older version number, it will be discared by the client.
What happens to the node containing stale data?
Read repair - As the client see that a specifc node is returning old value, client can send the update value to that node. This is called read repair.
Anti-Entropy - In some databases, replicas talk to each other via some background process where they keep comparing the data to find the differences. Merkle trees are generally used in dynamo style databases for anti entropy.
Quorums
Client generally sends a read/write request to all n nodes and atleast w of them must return success while writing and atleast r of them must return the response to a read request. So, the quorums logic for dynamo style databases is r+w should be greater than n for successful working of databases as-
if w < n, we can still process writes if a node is unavailable.
if r < n, we can still process reads if a node is unavailable.
Ex. n = 3, w = 2, r = 2. If one node is down, read and writes can still continue to work.
The limitations to dynamo style databases which uses quorums is the strong consistency. These databases are eventually consistent as there is a possibility of stale reads.
Sloppy Quorums and hinted handoffs
What if not all required w replicas are online for write operation? In that case, write can be made successful to some other y nodes which are not part of w nodes. This is called sloppy quorum but has a side effect of stale reads. When the offline node comes back online, data from y node is handover to that node. This is called hinted handoff.
Detecting concurrent writes
In order to become eventually consistent, the replicas should converge toward the same value. But how to detect if there is a conflict at first place? There are “happens-before” or casually related scenarios where A occurs before B or B occurs before A. If we can’t identify that situation, then conflict is there and needs to resolved using the ways mentioned above in Handling write conflicts.
LWW is only supported conflict resolution method in Cassandra and an optional feature in Riak.
Version vectors - Version vectors are the versions for a key maintained by different replicas. Version vectors help identify the heppened before cases and decide if the values can be merged or it can be kept as siblings for conflict resolution. Below picture represents the high level diagram of version vectors.
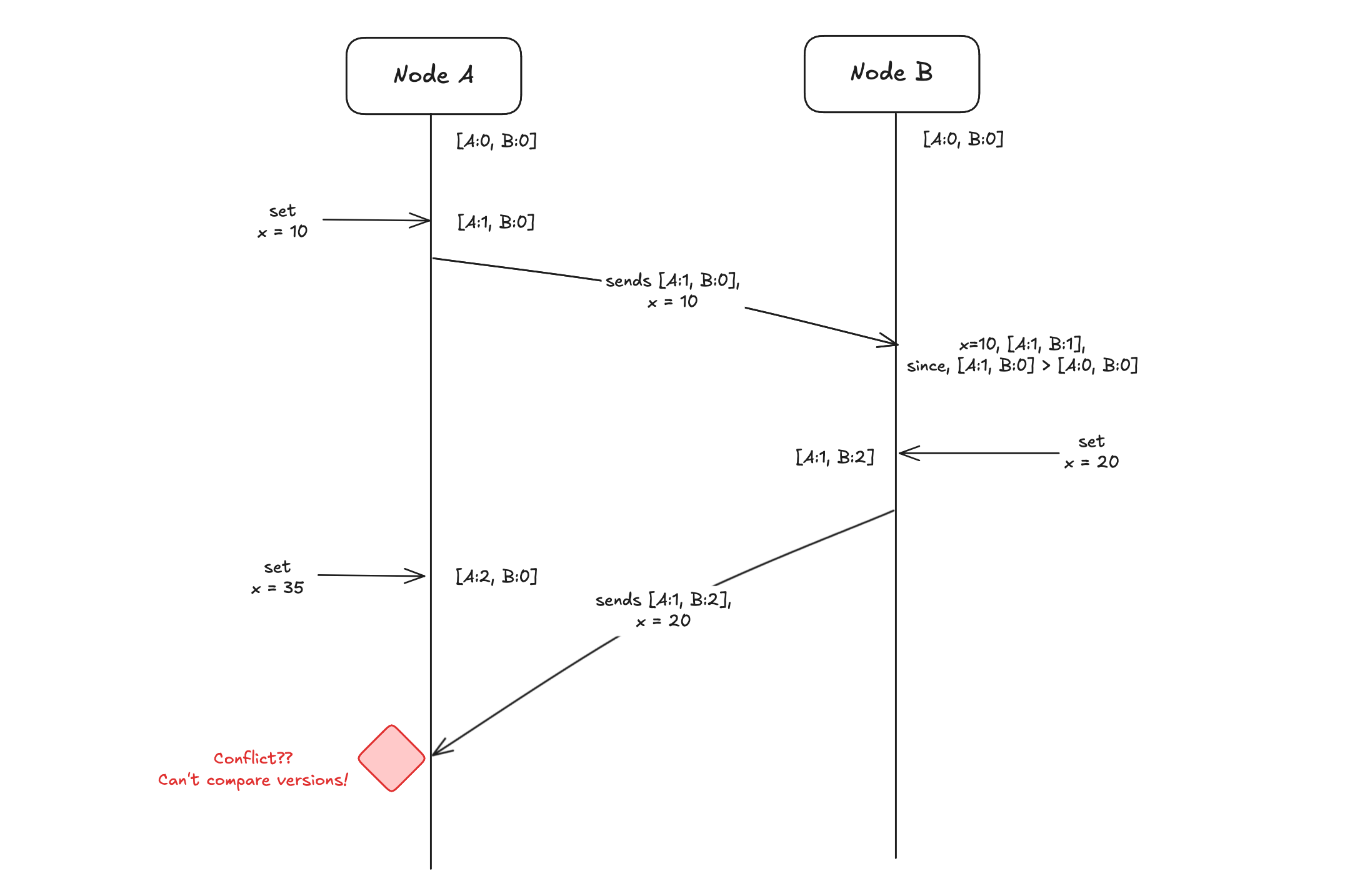
Problem with version vectors is sibling explosion which occurs when an object rapidly collects siblings that are not reconciled. Dotted version vectors implemented in Riak Db takes care of sibling explosion.
Conclusion
Moral of the story is simple - Every type of replication has its own pros and cons and developer has to study them in order to decide the best for their use case. So, rule of the thumb as per my understanding is that if you are okay with eventual consistency, then leaderless or multi-leader should be your way to go for replication as they provide better availability compared to single leader replication. However, single leader prefers consistency over availability.