
System Design - Calendar Application like Google Calendar/Outlook
How will you propose a design for Google Calendar in a system design interview?


1. Introduction
Have you ever wondered what goes on behind the scenes of popular calendar applications like Outlook or Google Calendar? How do they manage millions of events, synchronize across devices, and ensure you never miss an important meeting? This article takes you on a journey through the system design of a calendar application, a common challenge in system design interviews, specifically inspired by a recent discussion at Notion.
We'll dissect the core components, starting with the crucial phase of requirements gathering, defining what our calendar must do and how it should perform. From there, we'll delve into capacity estimations to understand the scale of the challenge, craft a robust API design for seamless interaction, and establish a clear data model to represent our core entities. Finally, we'll sketch out a high-level architectural blueprint and explore the intricate technical considerations that bring it all to life.
2. Requirements
2.1. Functional requirements
Create single or recurring events.
View daily, weekly, or monthly schedules.
Update or delete specific occurrences of a recurring event, or the entire series.
Provide meeting reminders before the event, e.g., 30 minutes prior.
2.2. Non functional requirements
High Availability: The service should always be up and running.
Eventually Consistent: Event invites and updates should reach every recipient within a few seconds, or at most, by 5 minutes.
Low Latency: Interactions should be quick and responsive.
Durable: Event data must never be lost.
3. Entities & APIs
3.1. Core entities
Our calendar revolves around these key data elements:
Event
Recipients
3.2. APIs
We can start with the following APIs, keeping in mind that their request and response structures might evolve during the interview discussion. For simplicity, let's begin with non-recurring meetings.
POST /eventBody:
{ eventName, startTimestamp, endTimeStamp, recipients, isRecurring, frequency, recStartTimestamp, recEndTimeStamp, ... }Response:
200
GET /event?eventId=Response:
200(success) |4XX(invalid requests) |5XX(server errors)
POST /event/update?eventId=qw91nsBody:
{ eventName, startTimestamp, endTimeStamp, recipients, ... }Response:
200
RRULE format is a widely recognized standard for defining recurring events. While we could certainly leverage that, for the sake of simplicity in this initial design, I've opted to explicitly include the necessary recurrence details like frequency, and the start and end timestamps of the recurrence.
4. Capacity estimates
Capacity estimations are crucial for understanding the scale of the system we need to build. In an interview setting, focus on providing rough estimates initially; you can dive deeper if necessary during the High-Level Design (HLD) discussion. Precision isn't the goal here—it's about grasping the scale, storage, and throughput.
Here are our assumptions:
Total Users: 100 million (100M).
Daily Schedulers: 1/10th of users (10M) schedule meetings daily.
Meetings Per User: Assume a user sets 5 meetings per day, leading to 50M meetings per day system-wide.
Average Event Size: 1 KB for event information.
Average Recipients Per Event: 10
Events Table Storage:
Daily:
50M daily meetings * 1 KB/meeting = 50 GB per day.10 Years:
(50 GB * 30 days/month * 12 months/year) * 10 years = 180 TB.Note: We'll need more storage for additional tables (e.g., users, reminders), which can be calculated later.
Read/write ratio:
Read vs. Write: Reads will vastly outnumber writes, as writes only occur during event creation or updates, but every recipient will read event info. We'll assume a 90:10 read-write ratio.
Daily Reads:
90M reads per day.Daily Writes:
10M writes per day.
Throughput:
Reads Per Second:
90,000,000 reads / (24 hours * 3600 seconds/hour) = 1041 reads/sec = ~1K reads/secWrites Per Second:
10,000,000 writes / (24 hours * 3600 seconds/hour) ≈ 115 writes/sec= ~100 writes/sec
These numbers give us a solid foundation for designing a system capable of handling the expected load and scale.
5. Getting started with simple design!
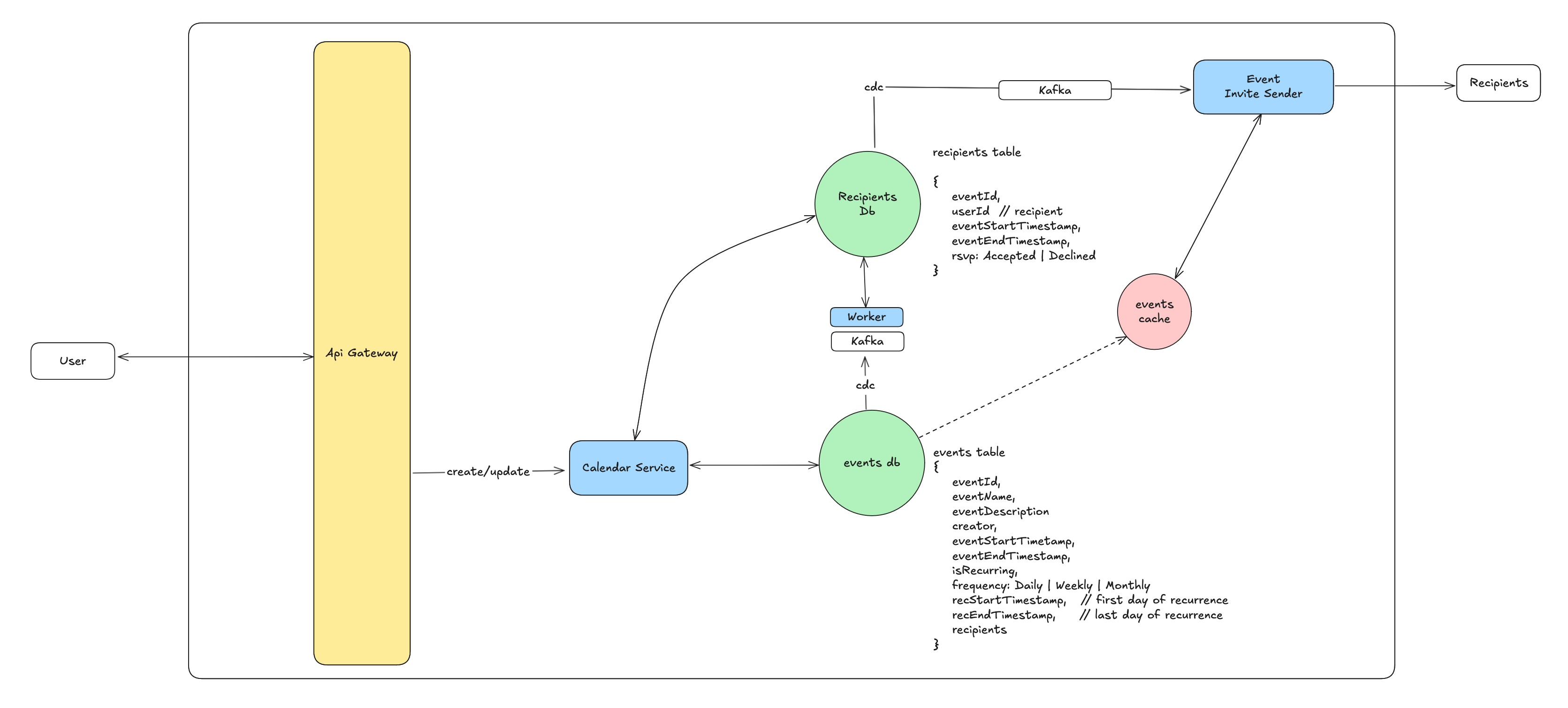
5.1. Main Components
API Gateway - As shown in the diagram, an API Gateway acts as our system's entry point. It's there to offload common tasks like authentication, authorization, and rate limiting, letting us focus on the core calendar logic itself. So, for now, consider user verification and permissions already handled.
Calendar Service - Our central component is the Calendar Service, which exposes all the necessary APIs. Event data will live in an events table, while recipient details will reside in a separate recipients table. (We're omitting the user table from this diagram to keep things focused.)
Tables - You might wonder why two tables? Storing all event and recipient data in one table would be highly inefficient. Imagine trying to find a user's events – you'd have to scan the entire database, which just won't scale.
To prevent increased latency and complex failure scenarios (like needing two-phase commits), the Calendar Service will not update both the events and recipients tables in a single operation. Instead, we'll use Change Data Capture (CDC). This means the Calendar Service writes to the events table, and those changes are then streamed (e.g., via Kafka – any distributed queue works) to dedicated worker servers. These workers are responsible for asynchronously updating the recipients table.
Event Invite Sender service - keeps an eye on the recipients database. When new recipient entries or updates appear, it's triggered to send out email notifications for event invitations. Just to clarify, this service handles the initial invite, not subsequent reminders; we'll delve into reminders later.
You'll also notice a cache(events cache). This is strategically placed to store recent event details, which the Invite Sender frequently needs to send notifications for each recipient, ensuring high performance.
5.2. Tables and Schema
Events Table Record
{
eventId,
eventName,
eventDescription
creator,
eventStartTimetamp,
eventEndTimestamp,
isRecurring,
frequency: Daily | Weekly | Monthly
recStartTimestamp, // first day of recurrence
recEndTimestamp, // last day of recurrence
recipients
} Recipients Table Record
{
eventId,
userId // recipient
eventStartTimestamp,
eventEndTimestamp,
rsvp: Accepted | Declined
}Our current design effectively addresses core functional needs:
Event Management: Users create/update events via the Calendar Service. Changes propagate asynchronously to the recipients table through CDC.
Event Viewing: Users query the
recipientstable (partitioned byuserId, sorted byeventStartTime) for their events, fetching details from theeventstable.Invite Notifications: The Event Invite Sender, monitoring recipient table updates, dispatches invite emails.
Now, let's look at the database.
5.3. Database selection
Choosing the right database is crucial for our estimated 180 TB over 10 years.
Option 1: Relational Database (e.g., PostgreSQL)
For PostgreSQL, our 180 TB storage demands sharding, as a single node tops out around 32 TB. Yearly sharding (e.g., 18 TB per shard) is a good fit. This maintains efficient range queries and handles our sub-1K QPS without throughput issues.
Option 2: NoSQL Database (e.g., Cassandra/DynamoDB)
NoSQL offers inherent horizontal scalability. The key is proper partition and sort key design:
Events Table: Partition by
eventId.Recipients Table: Partition by
userId, witheventStartTimestampas the sort key. This allows single-node queries for a user's events and efficient range queries (e.g., upcoming events).
Given the scale and read-write throughput, we can go with postgres to keep things simple.
6. Deep Dives
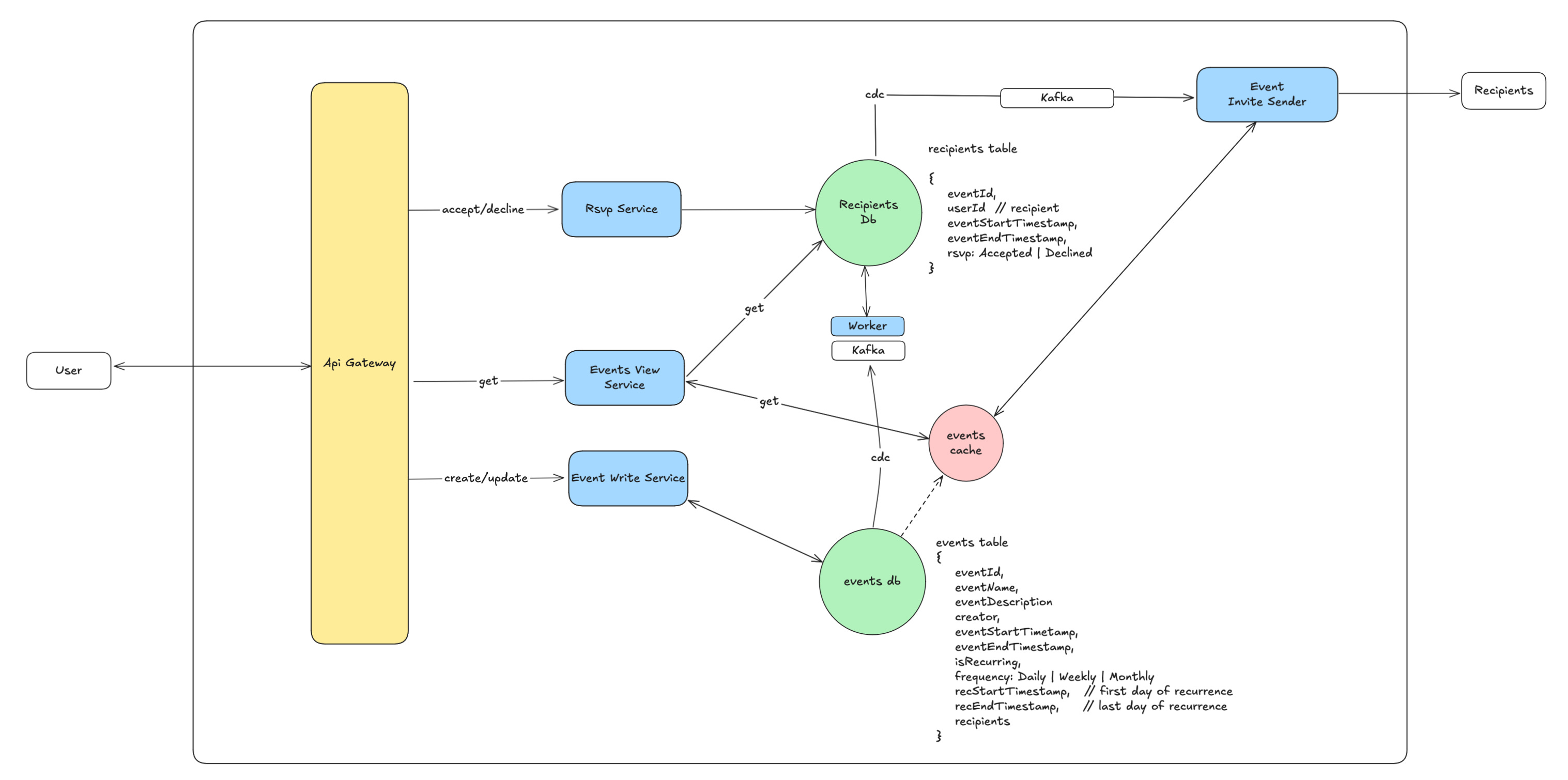
6.1. How to scale this solution?
To grow our system and keep it reliable, we need to scale effectively.
Services: The Calendar Service and Event Invite Sender are stateless, meaning we can easily add more copies of them (horizontal scaling) as demand rises.
Databases: Reads heavily outweigh writes (9:1 ratio). So, we'll scale them differently:
Writes: Handled by our primary database instance(s).
Reads: Served by many read replicas (or read-optimized NoSQL nodes) to keep things fast and take pressure off the write database. We can add a cache for weekly events view per user id if interviewer is okay with that.
RSVP Status: How we handle "Accepted/Declined" updates depends on scale:
Simple Start: We can update the recipients table directly through our main write path.
High Scale: If RSVPs become very frequent or complex, we might create a separate service just for RSVPs, allowing it to scale independently without affecting other parts of the system.
By separating these components and scaling them smartly, our calendar system can handle significant growth.
6.2. How to avoid sending duplicate invites?
To prevent sending duplicate event invitations, the Event Invite Sender service will maintain an invites table. This table will use a composite key of eventId + userId, ensuring that each recipient for a given event receives only one invitation.
6.3. How to handle recurring events?
So far, our design primarily focuses on individual event instances, with recipient updates flowing to the recipients table via CDC for speed. For recurring events, we'll adopt a more efficient strategy.
Instead of generating and storing every single occurrence of a recurring event in the database, we'll manage this at the application level. This means the client-side experience (CX) can dynamically generate and display the recurring instances based on the event's recurring pattern (e.g., daily, weekly, monthly) stored with the main event details. This approach avoids bloating our database with redundant entries for each recurrence, keeping our system lean and performant.
6.4. How to send event notifications 30 mins before the start time?
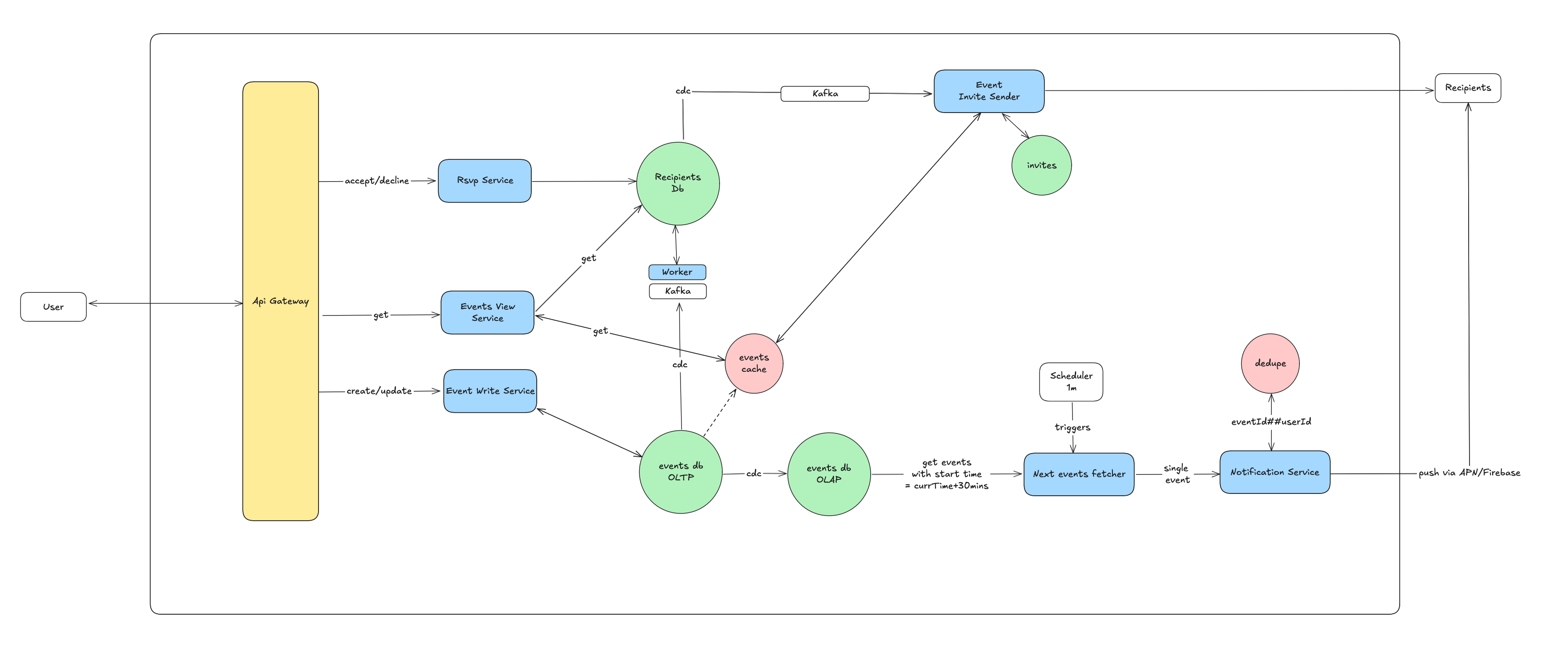
To ensure users get timely reminders, we'll build a separate notification pipeline. A dedicated scheduler will periodically trigger a service (like an AWS Lambda function). This service will query for all events starting 30 minutes from the current time. It then delegates the actual sending of push notifications for each event's recipients to a Notification Service. This Notification Service acts as a fan-out mechanism, ensuring that every relevant recipient receives their push notification. Notification service will handle if user is having multiple devices and whether he is using the dedicated calendar application or accessing the service via the browser.
6.5. What if there are hundreds or thousands of recipients?
Our initial design efficiently handles events with a few recipients by storing them directly. But what if an event has thousands of participants? Storing such a massive recipient list directly within the events table would become inefficient and unwieldy.
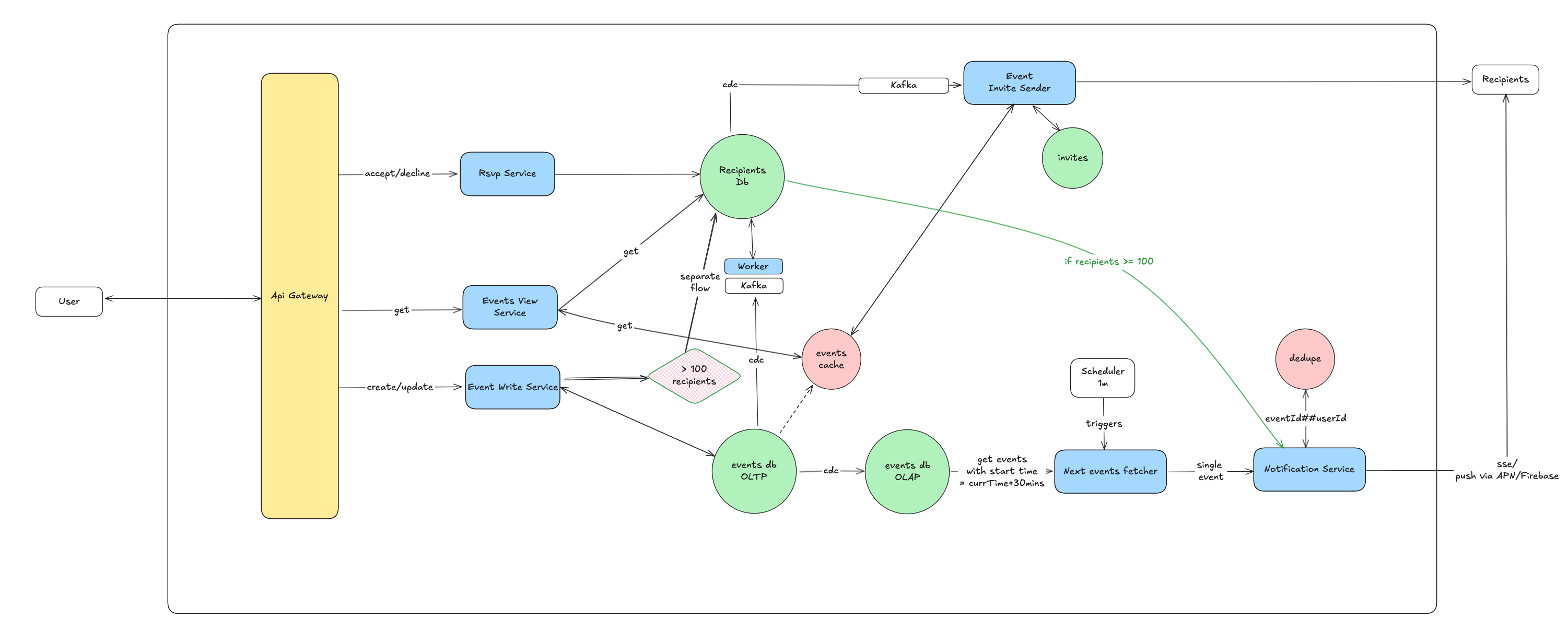
For events anticipated to have a very large number of recipients (e.g., over 1000), we'll implement a dedicated asynchronous flow:
Initial Event Creation (Without Full Recipient List): When a user creates a large event, the Write Service will insert the core event details into the
eventstable, but it will not embed the full recipient list directly. Instead, it might include a flag likelargeRecipientEvent: trueand/or a placeholder.Failure Mode: If this initial insertion fails, the user receives an immediate error, and no further steps are attempted.
Asynchronous Recipient Processing Trigger: Upon successful creation of the base event, the Events Write Service will then publish the event's
eventIdand the comprehensive recipient list to a new Kafka topic specifically designed for large event recipient processing. This decouples the event creation from the potentially time-consuming recipient management.Failure Mode: If the event is created successfully but the Kafka message fails to publish, the Calendar Service must compensate. It would trigger an asynchronous rollback (e.g., mark the event as "failed to create fully" or queue a deletion request for the
eventstable entry) and provide an appropriate error to the user, prompting a retry.
Dedicated Recipient Workers: A separate pool of worker services will continuously consume messages from this "large event recipient" Kafka topic. For each message:
These workers will fetch the large recipient list.
They will then efficiently insert individual recipient entries into the
recipientstable (potentially in batches for performance).Once all recipients are processed for an event, they might update the
eventstable (or a separate status table) to reflect that recipient processing is complete.
Impact on Existing Components:
Our existing CDC workers (which update the
recipientstable for smaller events) will need to be smart enough to ignoreeventstable changes for events marked aslargeRecipientEvent, as their recipients are handled by the new dedicated workers.The Event Invite Sender service will continue to listen to updates on the
recipientstable, ensuring invites are sent regardless of whether the event was small- or large-scale.
This split architecture ensures that the primary event creation path remains fast, while the complex and potentially high-volume task of managing thousands of recipients is handled efficiently and asynchronously, preventing it from bottlenecking the system.
Please note that it is exactly similar to the kafka+worker flow created for listening cdc of events table. This kafka+worker is explicitly for +100 recipient handling.
6.6. What if the invite sender fails for a specific recipient?
To ensure reliability for event invitations, we'll implement a Dead-Letter Queue (DLQ) solution for failures from the Event Invite Sender service.
Transient Errors: If an invite fails due to a temporary issue (e.g., network glitch), it's sent to a retry DLQ. Messages in this queue will be automatically retried after a set delay.
Permanent Errors: For persistent issues (e.g., invalid email addresses), the invite is moved to a non-retry DLQ. These errors require manual intervention for review and resolution, preventing endless retries of destined-to-fail messages.
Additionally, to keep event organizers informed, we can notify the event creator about any delivery failures to specific recipients.
7. Conclusion
From an interview perspective, designing a calendar application like this showcases your ability to tackle complex system design challenges holistically. We've demonstrated a strong grasp of requirements gathering, practical capacity estimations, API design, and database selection. Moreover, by addressing intricate concerns like recurring events, asynchronous processing for large recipient lists, and robust failure handling with DLQs, this design illustrates a pragmatic approach to building performant, scalable, and resilient distributed systems—critical skills for any senior engineering role.
Please feel free to comment if you find anything incorrect in this article. I will be happy to update the article if there are any mistakes.
Please share and subscribe Wild Wild Tech if you really like this article and want to get more in your inbox!
I see you are storing just one eventId and the recurring event handling is done on the client side
If a user deletes an instance of a recurring event how is that handled? since there is only one eventId how do you track changes to individual instances.